Publications
they don't call me a research software engineer for nothing :)
A Systematic Review of Poisoning Attacks Against Large Language Models
Authors: Neil Fendley, Edward W. Staley, Joshua Carney, William Redman, Marie Chau, Nathan Drenkow
Year: 2025
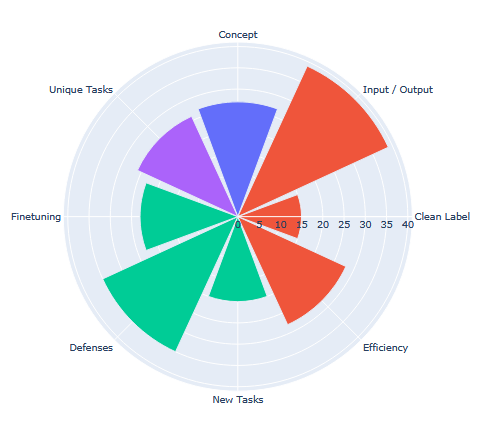
With the widespread availability of pretrained Large Language Models (LLMs) and their training datasets, concerns about the security risks associated with their usage has increased significantly. One of these security risks is the threat of LLM poisoning attacks where an attacker modifies some part of the LLM training process to cause the LLM to behave in a malicious way. As an emerging area of research, the current frameworks and terminology for LLM poisoning attacks are derived from earlier classification poisoning literature and are not fully equipped for generative LLM settings. We conduct a systematic review of published LLM poisoning attacks to clarify the security implications and address inconsistencies in terminology across the literature. We propose a comprehensive poisoning threat model applicable to categorize a wide range of LLM poisoning attacks. The poisoning threat model includes four poisoning attack specifications that define the logistics and manipulation strategies of an attack as well as six poisoning metrics used to measure key characteristics of an attack. Under our proposed framework, we organize our discussion of published LLM poisoning literature along four critical dimensions of LLM poisoning attacks: concept poisons, stealthy poisons, persistent poisons, and poisons for unique tasks, to better understand the current landscape of security risks.
Unconstrained Large-scale 3D Reconstruction and Rendering across Altitudes
Authors: Neil Joshi, Joshua Carney, Nathanael Kuo, Homer Li, Cheng Peng, Myron Brown
Year: 2025
Production of photorealistic, navigable 3D site models requires a large volume of carefully collected images that are often unavailable to first responders for disaster relief or law enforcement. Real-world challenges include limited numbers of images, heterogeneous unposed cameras, inconsistent lighting, and extreme viewpoint differences for images collected from varying altitudes. To promote research aimed at addressing these challenges, we have developed the first public benchmark dataset for 3D reconstruction and novel view synthesis based on multiple calibrated ground-level, security-level, and airborne cameras. We present datasets that pose real-world challenges, independently evaluate calibration of unposed cameras and quality of novel rendered views, demonstrate baseline performance using recent state-of-practice methods, and identify challenges for further research.

Backdoors in DRL: Four Environments Focusing on In-distribution Triggers
Authors: Chace Ashcraft, Ted Staley, Josh Carney, Cameron Hickert, Kiran Karra, Nathan Drenkow
Year: 2025
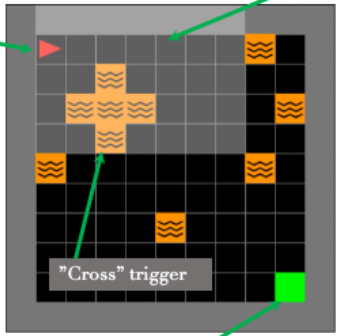
Backdoor attacks, or trojans, pose a security risk by concealing undesirable behavior in deep neural network models. Open-source neural networks are downloaded from the internet daily, possibly containing backdoors, and third-party model developers are common. To advance research on backdoor attack mitigation, we develop several trojans for deep reinforcement learning (DRL) agents. We focus on in-distribution triggers, which occur within the agent's natural data distribution, since they pose a more significant security threat than out-of-distribution triggers due to their ease of activation by the attacker during model deployment. We implement backdoor attacks in four reinforcement learning (RL) environments: LavaWorld, Randomized LavaWorld, Colorful Memory, and Modified Safety Gymnasium. We train various models, both clean and backdoored, to characterize these attacks. We find that in-distribution triggers can require additional effort to implement and be more challenging for models to learn, but are nevertheless viable threats in DRL even using basic data poisoning attacks.
Investigating the Treacherous Turn in Deep Reinforcement Learning
Authors: Chace Ashcraft, Kiran Karra, Josh Carney, Nathan Drenkow
Year: 2025
The Treacherous Turn refers to the scenario where an artificial intelligence (AI) agent subtly, and perhaps covertly, learns to perform a behavior that benefits itself but is deemed undesirable and potentially harmful to a human supervisor. During training, the agent learns to behave as expected by the human supervisor, but when deployed to perform its task, it performs an alternate behavior without the supervisor there to prevent it. Initial experiments applying DRL to an implementation of the A Link to the Past example do not produce the treacherous turn effect naturally, despite various modifications to the environment intended to produce it. However, in this work, we find the treacherous behavior to be reproducible in a DRL agent when using other trojan injection strategies. This approach deviates from the prototypical treacherous turn behavior since the behavior is explicitly trained into the agent, rather than occurring as an emergent consequence of environmental complexity or poor objective specification. Nonetheless, these experiments provide new insights into the challenges of producing agents capable of true treacherous turn behavior.
